Dr. Mike Lloyd looks at the year ahead for businesses and security and why having an up-to-date, realistic blueprint of your network is now more important than ever.
Barely two months into the New Year and already we face tales of new cybersecurity incidents are flooding in. Whether it’s the theft of sensitive customer data, corporate espionage, damaging ransomware-related outages or state-sponsored hacking, the risks have never been greater. And no organisation can claim to be 100% safe. But with UK firms each suffering an estimated 230,000 attacks on average in 2016, the focus must now be on building resilience into corporate networks to ensure the coming year is a more secure one for organisations.
https://www.redseal.net/wp-content/uploads/2017/03/Why-Its-Time-for-a-New-Approach-to-Network-Security.jpg12961728RedSealhttps://www.redseal.net/wp-content/uploads/2016/08/RedSeal-logo.pngRedSeal2017-03-02 09:30:162023-01-20 16:24:10Why It’s Time for a New Approach to Network Security
“When we build quickly, in a world of accelerating change, we always tend to build fragile.”
Forbes Technology Council members are in a wide range of industries and come from a diverse set of experiences. However, they all have lots of great insights to share, from best practices for technology departments to smart predictions for the future of tech. To showcase their expertise, we’re profiling Forbes Technology Council members here on the blog. This week: Dr. Mike Lloyd.
Dr. Mike Lloyd is CTO of RedSeal, a company producing a network modeling and risk scoring platform for building digitally resilient organizations. RedSeal’s Digital Resilience Score, modeled after a creditworthiness score, measures how prepared an organization is to respond to an incident and quickly rebound. Lloyd has more than 25 years of experience modeling and controlling fast-moving, complex security and network systems.
https://www.redseal.net/wp-content/uploads/2016/08/RedSeal-logo.png00RedSealhttps://www.redseal.net/wp-content/uploads/2016/08/RedSeal-logo.pngRedSeal2017-02-28 07:52:152020-05-19 09:32:15Meet Dr. Mike Lloyd, CTO at RedSeal
The Internet of Things crashed into the old Internet on Oct 21st, and it wasn’t pretty. A specialized but fairly simple bit of malware known as Mirai was used to cause huge numbers of simple Internet-connected devices (cameras, home routers, baby monitors, etc.) to flood the infrastructure of a service provider called Dyn. This caused widespread collateral damage across the traditional world of social media and entertainment websites.
https://www.redseal.net/wp-content/uploads/2016/08/RedSeal-logo.png00Dr. Mike Lloyd, CTO, RedSealhttps://www.redseal.net/wp-content/uploads/2016/08/RedSeal-logo.pngDr. Mike Lloyd, CTO, RedSeal2017-02-17 11:00:382018-12-10 13:01:15The Internet of Things That Can Attack You
Some people are surprised that Heartbleed is still out there, 3 years on, as you can read here. What this illustrates is two important truths of security, depending on whether you see the glass half full or half empty.
One perspective is that, once again, we know what to do, but failed to do it. Heartbleed is well understood, and directly patchable. Why haven’t we eradicated this by now? The problem is that the Internet is big. Calling the Internet an “organization” would be a stretch – it’s larger, more diverse, and harder to control than any one organization. But if you’ve tried to manage vulnerabilities at any normal organization – even a global scale one – you have a pretty good idea how hard it gets to eliminate any one thing. It’s like Zeno’s Paradox – when you try to eradicate any one problem you choose, you can fix half the instances in a short period of time. The trouble is that it takes about that long again to fix the next half of what remains, and that amount again for the half after that. Once you’ve dealt with the easy stuff – well known machines, with well documented purpose, and a friendly owner in IT – it starts to get hard fast, for an array of reasons from the political to the technical. You can reduce the prevalence of a problem really quickly, but to eradicate it takes near-infinite time. And the problem, of course, is that attackers will find whatever you miss – they can use automation to track down every defect. (That’s how researchers found there is still a lot of Heartbleed out there.) Any one time you miss might open up access to far more important parts of your organization. It’s a chilling prospect, and it’s fundamental to the unfair fight in security – attackers only need one way in, defenders need to cover all possible paths.
To flip to the positive perspective, perhaps the remaining Heartbleed instances are not important – that is, it’s possible that we prioritized well as a community, and only left the unimportant instances dangling for all this time. I know first-hand that major banks and critical infrastructure companies scrambled to stamp out Heartbleed from their critical servers as fast as they could – it was impressive. So perhaps we fixed the most important gaps first, and left until later any assets that are too hard to reach, or better yet, have no useful access to anything else after they are compromised. This would be great if it were true. The question is, how would we know?
The answer is obvious – we’d need to assess each instance, in context, to understand which instances must get fixed, and which can be deferred until later, or perhaps until after we move on to the next fire drill, and the fire drill after that. The security game is a never-ending arms race, and so we always have to be responsive and dynamic as the rules of the game change. So how would we ever know if the stuff we deferred from last quarter’s crises is more important or less important than this quarter’s? Only automated prioritization of all your defensive gaps can tell you.
https://www.redseal.net/wp-content/uploads/2016/08/RedSeal-logo.png00Dr. Mike Lloyd, CTO, RedSealhttps://www.redseal.net/wp-content/uploads/2016/08/RedSeal-logo.pngDr. Mike Lloyd, CTO, RedSeal2017-02-06 05:00:122018-08-14 08:57:28The Bleed Goes On
Mike Lloyd, CTO at RedSeal, argues that more granular control is a good thing, but it’s easier said than done.
There’s a lot going on in virtual data centres. In security, we’re hearing many variations of the term “micro-segmentation”. (It originated from VMware, but has been adopted by other players, some of them adding spin.)
https://www.redseal.net/wp-content/uploads/2016/08/RedSeal-logo.png00Dr. Mike Lloyd, CTO, RedSealhttps://www.redseal.net/wp-content/uploads/2016/08/RedSeal-logo.pngDr. Mike Lloyd, CTO, RedSeal2016-09-27 13:58:172018-08-14 08:57:36Micro-Segmentation: Good or bad?
There’s a lot going on in virtual data centers. In security, we’re hearing many variations of the term “micro-segmentation.” (It originated from VMWare, but has been adopted by other players, some of them adding top-spin or over-spin.)
We know what segmentation is. Every enterprise network practices segmentation between outside and inside, at least. Most aim to have a degree of internal segmentation, but I see a lot more planning than doing — unless an audit is on the line. Many networks have a degree of segmentation around the assets that auditors pay attention to, such as patient records and credit cards. There are organizations further up the security sophistication curve who have a solid zone-based division of their business, can articulate what each zone does and what should go on between them, and have a degree – at least some degree – of enforcement of inter-zone access. But these tend to be large, complex companies, so each zone tends to be quite large. It’s simple math – if you try to track N zones, you have to think about N2 different relationships. That number goes up fast. Even well-staffed teams struggle to keep up with just a dozen major zones in a single network. That may not sound like a lot, but the typical access open between any two zones can easily exceed half a million communicating pairs. Auditing even one of those in full depth is a super-human feat.
Now along comes the two horses pulling today’s IT chariot: the virtual data center and the software defined network. These offer more segmentation, with finer control, all the way down to the workload (or even lower, depending on which marketing teams you believe). This sounds great – who wouldn’t want super-fine controls? Nobody believes the perimeter-only model is working out any more, so more control must be better, right? But in practice, if you just throw this technology onto the existing stack without a plan for scaling, it’s not going to work out.
If you start with a hard-to-manage, complex management challenge, and you respond by breaking it into ever smaller pieces, spread out in more places, you can rapidly end up like Mickey Mouse in The Sorcerer’s Apprentice, madly splitting brooms until he’s overrun.
Is it hopeless? Certainly not. The issue is scale. More segmentation, in faster-moving infrastructure, takes a problem that was already tough for human teams and makes it harder. But this happens to be the kind of problem that computers are very good at. The trick is to realize that you need to separate the objective – what you want to allow in your network – from the implementation, whether that’s a legacy firewall or a fancy new GUI for managing policy for virtual workloads. (In the real world, that’s not an either/or – it’s a both, since you have to coordinate your virtual workload protections with your wider network, which stubbornly refuses to go away just because it’s not software defined.)
That is, if you can describe what you want your network to do, you can get a big win. Just separate your goals from the specific implementation – record the intention in general terms, for example, in the zone-to-zone relationships of the units of your business. Then you can use automation software to check that this is actually what the network is set up to do. Computers don’t get tired – they just don’t know enough about your business or your adversaries to write the rules for you. (I wouldn’t trust software to figure out how an organism like a business works, and I certainly wouldn’t expect it to out-fox an adversary. If we can’t even make software to beat a Turing Test, how could an algorithm understand social engineering – still a mainstay of modern malware?)
So I’m not saying micro-segmentation is a bad thing. That’s a bit like asking whether water is a bad thing – used correctly, it’s great, but it’s important not to drown. Here, learning to swim isn’t about the latest silver bullet feature of a competitive security offering – it’s about figuring out how all your infrastructure works together, and whether it’s giving the business what’s needed without exposing too much attack surface.
https://www.redseal.net/wp-content/uploads/2016/08/RedSeal-logo.png00Dr. Mike Lloyd, CTO, RedSealhttps://www.redseal.net/wp-content/uploads/2016/08/RedSeal-logo.pngDr. Mike Lloyd, CTO, RedSeal2016-09-19 16:00:592018-08-14 08:57:44Micro-Segmentation: Good or Bad?
Most people think about network infrastructure about as much as they think about plumbing – which is to say, not at all, until something really unfortunate happens. That’s what puts the “infra” in the infrastructure – we want it out of sight, out of mind, and ideally mostly below ground. We pay more attention to our computing machinery, because we use them directly to do business, to be sociable, or for entertainment. All of these uses depend critically on the network, but that doesn’t mean most of us want to think about the network, itself.
That’s why SEC Consult’s research into exploitable routers probably won’t get the attention it deserves. That’s a pity – it’s a rich and worthwhile piece of work. It’s also the shape of things to come, as we move into the Internet of Things. (I had a great conversation a little while ago with some fire suppression engineers who are increasingly aware of cyber issues – we were amused by the concept of The Internet of Things That Are on Fire.)
In a nutshell, the good folks at SEC Consult searched the Internet for objects with a particular kind of broken cryptography – specifically, with known private keys. This is equivalent to having nice, shiny locks visible on all your doors, but all of them lacking deadbolts. It sure looks like you’re secure, but there’s nothing stopping someone simply opening the doors up. (At a minimum, the flaw they looked for makes it really easy to snoop on encrypted traffic, but depending on context, can also allow masquerading and logging in to control the device.)
And what did they find when they twisted doorknobs? Well, if you’ve read this far, you won’t be surprised that they uncovered several million objects with easily decrypted cryptography. Interestingly, they were primarily those infrastructure devices we prefer to forget about. Coincidence? Probably not. The more we ignore devices, the messier they tend to get. That’s one of the scarier points about the Internet of Things – once we have millions or billions of online objects, who will take care of patching them? (Can they be updated? Is the manufacturer responsible? What if the manufacturer has gone out of business?)
But what really puts the icing onto the SEC Consult cake is that they tried hard to report, advertise, and publicize everything they found in late 2015. They pushed vendors; they worked with CERT teams; they made noise. All of this, of course, was an attempt to get things to improve. And what did they find when they went back to scan again? A 40% increase in devices with broken crypto! (To put the cherry onto that icing, the most common device type they reported before has indeed tended to disappear. Like cockroaches, if you kill just one, you’re likely to find more when you look again.)
So what are we to conclude? We may wish our infrastructure could be started up and forgotten, but it can’t be. It’s weak, it’s got mistakes in it, and we are continuously finding new vulnerabilities. One key take-away about these router vulnerabilities: we should never expose management interfaces. That sounds too trivial to even mention – who would knowingly do such a thing? But people unknowingly do it, and only find out when the fan gets hit. When researchers look (and it gets ever easier to automate an Internet-wide search), they find millions of items that violate even basic, well-understood practices. How can you tell if your infrastructure has these mistakes? I’m not saying a typical enterprise network is all built out of low-end routers with broken crypto on them. But the lessons from this research very much apply to networks of all sizes. If you don’t harden and control access to your infrastructure, your infrastructure can fail (or be made to fail), and that’s not just smelly – it’s a direct loss of digital resilience. And that’s something we can’t abide.
https://www.redseal.net/wp-content/uploads/2016/09/RedSeal_Holey-Routers_Network-Infrastructure.jpg9341400Dr. Mike Lloyd, CTO, RedSealhttps://www.redseal.net/wp-content/uploads/2016/08/RedSeal-logo.pngDr. Mike Lloyd, CTO, RedSeal2016-09-12 16:27:422018-08-14 08:57:52Hol(e)y Routers, Batman!
I recently came across a rather nice title for a webinar by A10 Networks’ Kevin Broughton– “Hide & Sneak: Defeat Threat Actors Lurking within your SSL Traffic”. “Hide & Sneak” is a good summary of the current state of the cybersecurity game. Whether our adversaries are state actors or less organized miscreants, they find plenty of ways to hide, stay quiet and observe. They can keep this up for years at a time. Our IT practices of the last few decades have engineered very effective business systems. On the other hand, they are sprawling and complex systems, made up of tunnels, bridges and pipes — much of which is out of sight, unless you take special pains to go look in every corner.
The “Hide & Sneak” webinar focuses on SSL, just one aspect of just one kind of encryption used in just one kind of VPN. This is worthwhile – I mean no criticism of the content offered. But if we think about how complex just this one widely used piece of infrastructure is, and then take a step back to think about this level of detail multiplied across all the technologies we depend on, it’s obvious that it’s impossible for any single security professional to understand all the layers, all the techniques, and all the complexity involved in mission-critical networks. Given staff shortages, it’s not even possible for a well-funded team to keep enough expertise in-house to deal in full depth with everything involved in today’s networks, let alone keep up with the changes tomorrow.
If we can’t even hire experts in all aspects of all the technologies we use, how can we defend our mission-critical infrastructure?
We can break the problem down into three parts – understanding the constantly-shifting array of technologies we use; keeping up with the continuous stream of new defects, issues and best practices; and thinking through the motivations, strategies and behaviors of bad actors. Of these three, the first two are highly automatable (and essentially impossible without automation). The third is the ideal domain for humans – no computer has the wit or insight to think strategically about an intelligent, wily adversary. This is why automation is best focused on understanding the infrastructure, and on uncovering and prioritizing vulnerabilities and defensive gaps.
The best security teams focus human effort on the human problem – understanding the thought patterns of the adversaries, not on learning every detail of every aspect of every technology we use.
https://www.redseal.net/wp-content/uploads/2016/08/RedSeal-logo.png00Dr. Mike Lloyd, CTO, RedSealhttps://www.redseal.net/wp-content/uploads/2016/08/RedSeal-logo.pngDr. Mike Lloyd, CTO, RedSeal2016-09-06 15:00:322018-08-14 08:57:59“Hide & Sneak.” Playing Today’s Cybersecurity Game
The latest revelations about firewall vulnerabilities stolen and leaked by the Shadow Brokers are very scary, but not all that new. We learn about the release of a major infrastructure vulnerability about once every six months or so. Organizations that have learned to focus on resilience — knowing their network and how to operate through a threat — are in the best position to respond.
With each new revelation, every defender has to scramble to answer the same three basic questions: do I have this problem? Where? Is it exposed? In today’s situation with weaponized vulnerabilities in major firewalls, the first question is easy to answer (if unfortunate). It seems that almost every major network has instances of these vulnerable products as part of their security defenses. The second and third questions require mapping the vulnerability into your own network. Do you have wide open access, or, effective internal segmentation? For this disclosure, have you properly locked down the important protocol known as SNMP? Once you can answer these questions, you are ready to begin incident response based on any surprises you turn up.
Imagine you’re responsible for a physical building, and you put up doors marked “Authorized Personnel Only”. That’s an important thing to do. Whether you run a retail store, a corporate office, or a cruise ship, you need to keep some critical infrastructure and access in a special zone. Now imagine forgetting to put those signs on some of the doors, or worse, leaving them open – perhaps through simple oversight, rushing to build out your business, or as you adapt to changing times. And, the only way you could know if you have a problem is to walk through every single hallway to check. If you don’t know or can’t tell whether your restricted areas are solid, then incidents are much scarier. This is the issue behind the latest revelations. It’s an important industry-wide best practice to isolate important network management protocols in a special zone, similar to the “Authorized Personnel Only” part of many buildings. But organizations everywhere have to scramble to see whether they have done this properly in light of the new vulnerabilities in those protocols.
RedSeal users can see where they stand with just a few clicks.
To read more, including step by step instructions for using RedSeal to answer these critical questions, see here.
For a demonstration of how you can use RedSeal to understand the extent of the problem in your specific network, watch our video.
https://www.redseal.net/wp-content/uploads/2016/08/RedSeal-logo.png00Dr. Mike Lloyd, CTO, RedSealhttps://www.redseal.net/wp-content/uploads/2016/08/RedSeal-logo.pngDr. Mike Lloyd, CTO, RedSeal2016-08-18 15:24:262018-08-14 08:58:07Responding to the Shadow Broker Vulnerabilities
Recent press coverage has focused a lot of attention on some long-hidden vulnerabilities in firewalls. Network security teams are scrambling to understand whether they are exposed, and to what extent. These notes show how you can use RedSeal to understand the extent of the problem in your specific network.
This is not the only vulnerability found in the “Shadow Broker” files, but serves as a good working example. The nature of the vulnerability is a flaw in SNMP, which is very commonly used as an important function of network infrastructure. Simply disabling SNMP is not generally a viable workaround, since SNMP is a vital part of network visibility. (Even if your windshield has a crack in it, it’s not a good response to paint it black.) Instead, organizations have to understand whether they have properly limited access to the vulnerable protocol, and where the locations are that need access.
In other words, a network is in poor shape if anyone, anywhere inside the network can use SNMP to communicate with the firewalls. In that scenario, an attacker anywhere inside the organization can compromise a firewall — an extremely undesirable situation. Such an attacker can surreptitiously monitor traffic, since firewalls are often at critical choke points in networks with a view into all boundary-crossing flows. Worse, if the attacker wants to be disruptive to operations, there are few locations as powerful as a main firewall to cut off the ability of an organization to function and respond.
A well-built organization does not allow SNMP access from anywhere to their key network infrastructure. Instead, they limit access, since SNMP is useful, but not needed by most people in an organization to do their jobs. It has long been a best practice in network architecture to limit access for SNMP only to those locations that need it. But which locations are those exactly? An organization responding to the “Shadow Broker” disclosures has to scramble to quickly understand where they allow SNMP, since these locations are the critical attack surface for these newly revealed attacks.
Finding Access to Firewalls
With RedSeal, it’s very easy to find out whether you are wide open to these SNMP attacks, and if not, to locate where you allow access.
Step 1: Bring up the Security Intelligence Center, using the yellow light bulb icon in the icon bar:
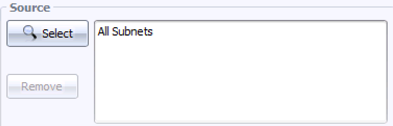
Step 2: On the left, under Source, click Select, then Browse, then All Subnets, then Replace. This sets the source for the query to “anywhere”. You should see this:
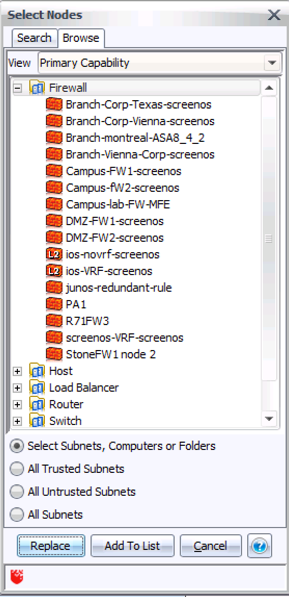
Step 3: On the right, under Destination, click Select, then Browse, and change the View to Primary Capability. Open the Firewall folder, like this:
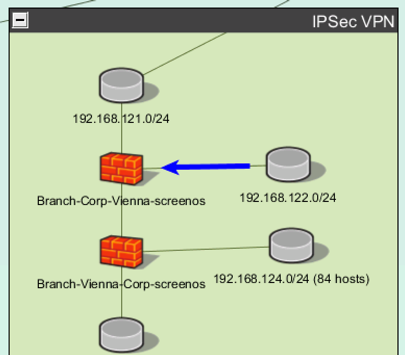
Step 4: To start with, pick just one firewall – in this example, I’ll take the second one on the list, from Vienna. Hit Replace to add this to the query dialog.
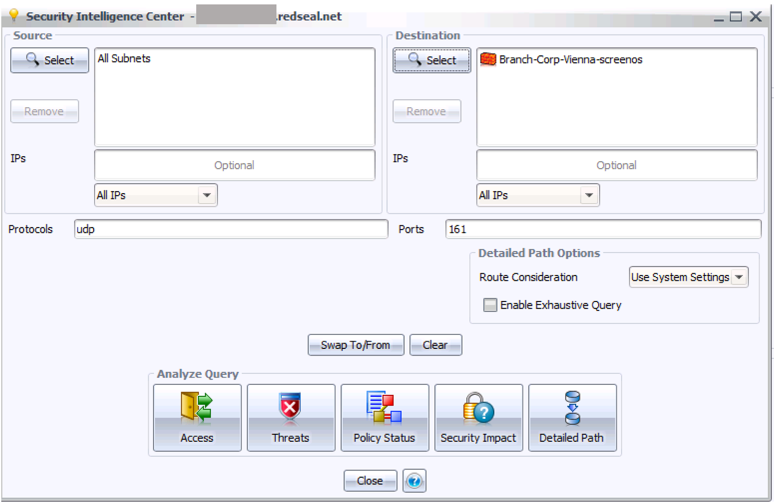
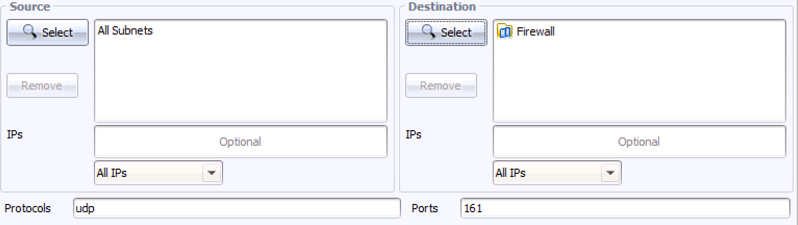
Step 5: In the Protocols field, enter “udp” (without the quote marks) and in the Ports field, enter “161”. This is the port and protocol for basic SNMP communication. The query dialog now looks like this:
Step 6: Click the Access button in the icon bar at the bottom. This will show you a table of all access to the given firewall – in this case, just one row:
Step 7: To see this visually, click “Show In Topo” at the bottom of this result. This will take you to the network map, and highlight where you have SNMP access to the firewall.
This is a “good” result. Only one location in the network can use SNMP to reach this firewall. There is still risk – it’s important to investigate any defects, vulnerabilities, or indicators of compromise from the source side of this arrow. But fundamentally, this firewall was secured following best practices – the total amount of the network that can access the SNMP management plane of this device is very limited.
However, in real world networks, the answer will often be messier. RedSeal recommends following the above steps for only one firewall at first, to look at the extent of SNMP access. If your organization shows a good result for the first few firewalls, this is reassuring, but can then lead to harder questions. For example, we can ask a much wider question, covering all the firewalls at once. This should only be attempted after looking at a few individual firewalls, since the full query can generate an overwhelming amount of data.
To ask this broader question, go back to step 4 – in the Security Intelligence Center dialog, click Select on the right, under Destination. Rather than picking one firewall off the list, we can select the folder of all firewalls, then click Replace. The query dialog now looks like this:
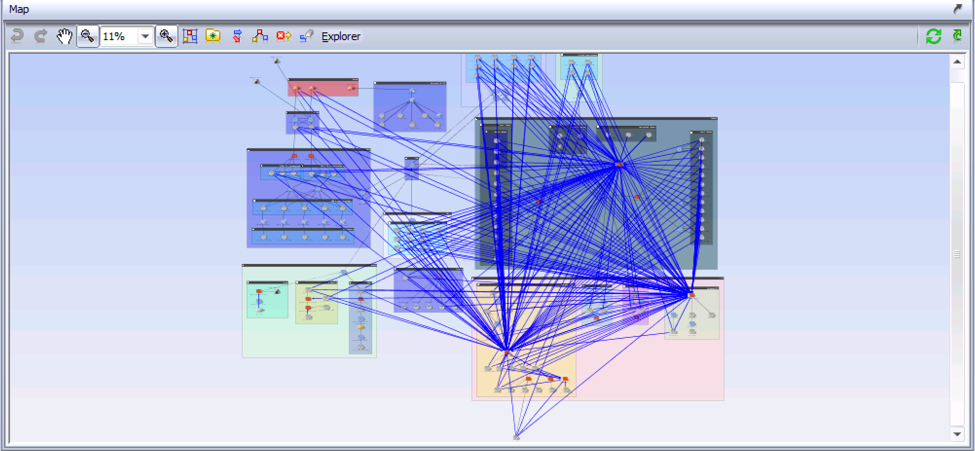
Even in a relatively small network, this generates a lot of information. We can look at the answer visually, using Show in Topo:
Clearly, this network has not followed the best practice design of limiting access to all firewalls. Each blue arrow represents some location that has access to a firewall over SNMP. It is not plausible that so many locations in this network need that access to perform their job functions. This network needs to focus on internal segmentation.
Checking Firewall Code Versions
As the various vendors release updates, it’s important to track whether you have firewalls that need to be updated urgently – especially those with very wide access. You can use RedSeal to generate a summary report on the types of firewalls you have, and which versions of software they are running. One way to report on firewalls by version is as follows:
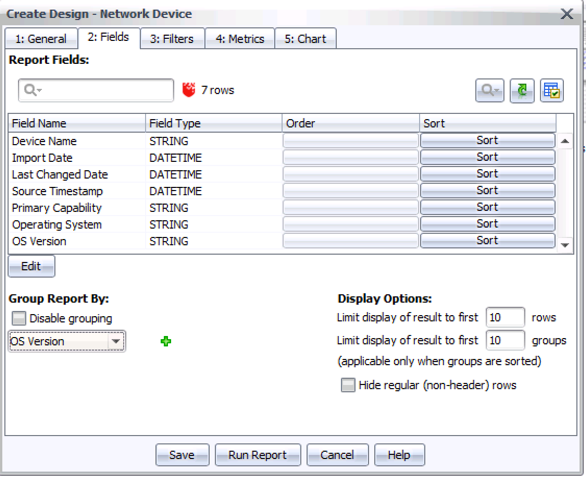
Step 1: Open Reports tab, select Security Model in the left hand list of reporting areas.
Step 2: Click the + button to create a new report, and select a data type of Network Device
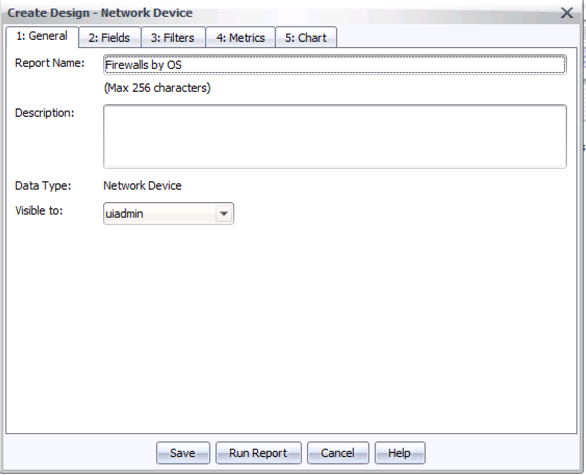
Step 3: On the first tab, name your report “Firewalls by OS” (without the quotes – or pick your own name for the report), like this:
Step 4: On the second tab (Fields), click Edit, select OS Version on the left list, and click Add to add it to the list of fields in the report. Click OK.
Step 5: Under Group Report By, change the grouping to “OS Version”
Step 6: Under Display Options, enter 10 in “Limit display of results to the first N rows”. (This is to abbreviate the report, at least initially. Some organizations have a great many firewalls, and the first thing to do is to figure out which OS versions you have, with a few listed examples, before digging through too large of an inventory report.)
By this point, tab 2 should look as follows:
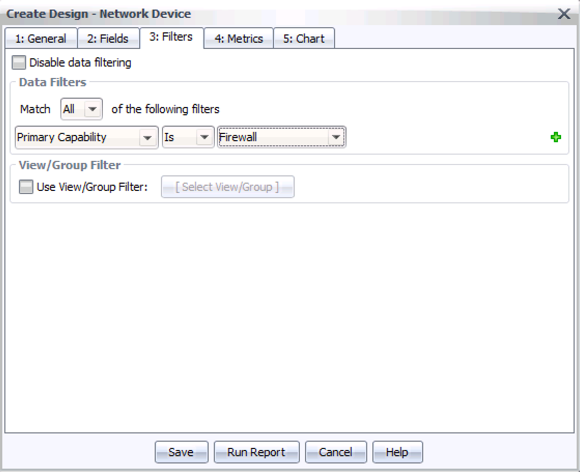
Step 7: Change to tab 3, Filters, and under “Match All”, add a rule for “Primary Capability”, then “Is”, then “Firewall”, like this:
Step 8: Hit Save. The default choices on tabs 4 and 5 will work well here, to include some counts and a chart.
Step 9: On the Reports tab, run your new report by double-clicking the icon above “Firewalls by OS” (or whatever name you gave your report).
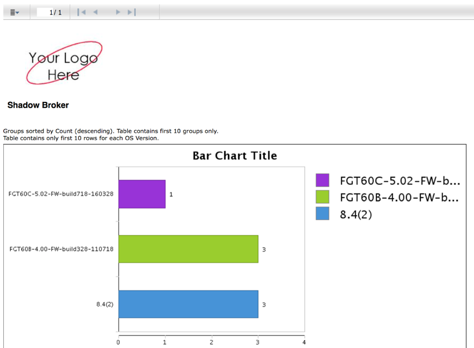
Your browser will pop up requesting log in (if you haven’t logged in previously), then will display a report summary chart like this:
You may want to focus first on the smaller bars – the unusual outliers in your network infrastructure. This is where overlooked problems – in this case, well down-rev firewall operating systems – can lurk. The report details will include a sample of the firewalls running each code image in your environment, like this:
As the firewall vendors move to produce new releases to close off these vulnerabilities, you can use a report like this to track how well your operational teams are deploying these important updates.
Conclusions
The recently uncovered vulnerabilities, which appear to have been in use for many years, are further proof that we need to keep our houses in order. An organization with good discipline about internal segmentation, with a well separated network management infrastructure, has less to worry about with these new revelations. But even that organization needs rapid ways to assess whether the discipline has really held up in practice. Are there gaps? If so, where? Even the locations that do have SNMP access to firewalls, are they easy or hard for an attacker to break into? All of these questions are easy to answer if you have the ability to analyze your as-built, rapidly evolving network infrastructure. RedSeal makes it easy to find answers to these vital questions.
https://www.redseal.net/wp-content/uploads/2016/08/RedSeal-logo.png00Dr. Mike Lloyd, CTO, RedSealhttps://www.redseal.net/wp-content/uploads/2016/08/RedSeal-logo.pngDr. Mike Lloyd, CTO, RedSeal2016-08-18 15:19:292018-08-14 08:59:42Using RedSeal to Understand Access to the “Shadow Broker” Firewall Vulnerabilities
In order to provide you with the best experience possible we might sometimes track information about you. Sometimes this may involve writing a cookie. We use this information for things like experience enrichment, analytics and targeting advertising. We recommend allowing these functions to get the most out of your experience.
We may request cookies to be set on your device. We use cookies to let us know when you visit our websites, how you interact with us, to enrich your user experience, and to customize your relationship with our website.
Click on the different category headings to find out more. You can also change some of your preferences. Note that blocking some types of cookies may impact your experience on our websites and the services we are able to offer.
Essential Website Cookies
These cookies are strictly necessary to provide you with services available through our website and to use some of its features.
Because these cookies are strictly necessary to deliver the website, refusing them will have impact how our site functions. You always can block or delete cookies by changing your browser settings and force blocking all cookies on this website. But this will always prompt you to accept/refuse cookies when revisiting our site.
We fully respect if you want to refuse cookies but to avoid asking you again and again kindly allow us to store a cookie for that. You are free to opt out any time or opt in for other cookies to get a better experience. If you refuse cookies we will remove all set cookies in our domain.
We provide you with a list of stored cookies on your computer in our domain so you can check what we stored. Due to security reasons we are not able to show or modify cookies from other domains. You can check these in your browser security settings.
Other external services
We also use different external services like Google Webfonts, Google Maps, and external Video providers. Since these providers may collect personal data like your IP address we allow you to block them here. Please be aware that this might heavily reduce the functionality and appearance of our site. Changes will take effect once you reload the page.