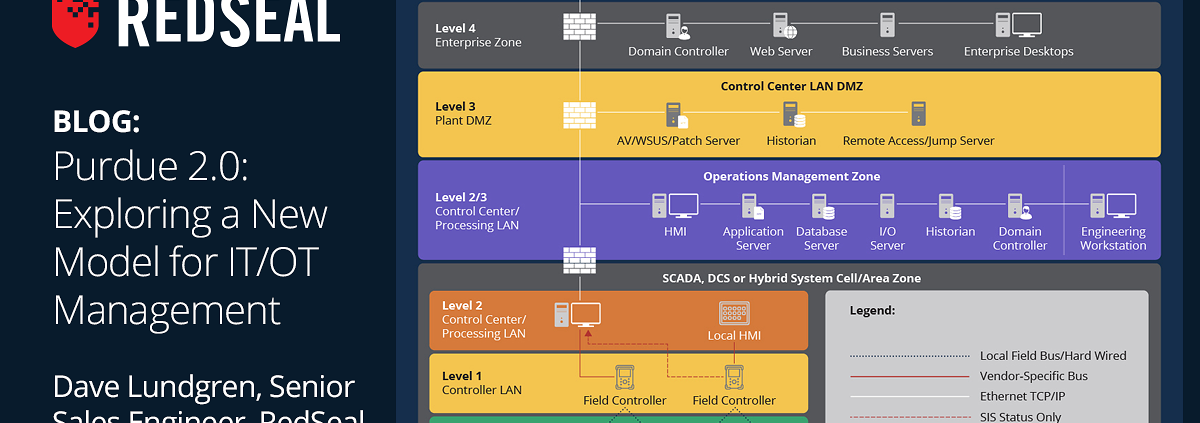
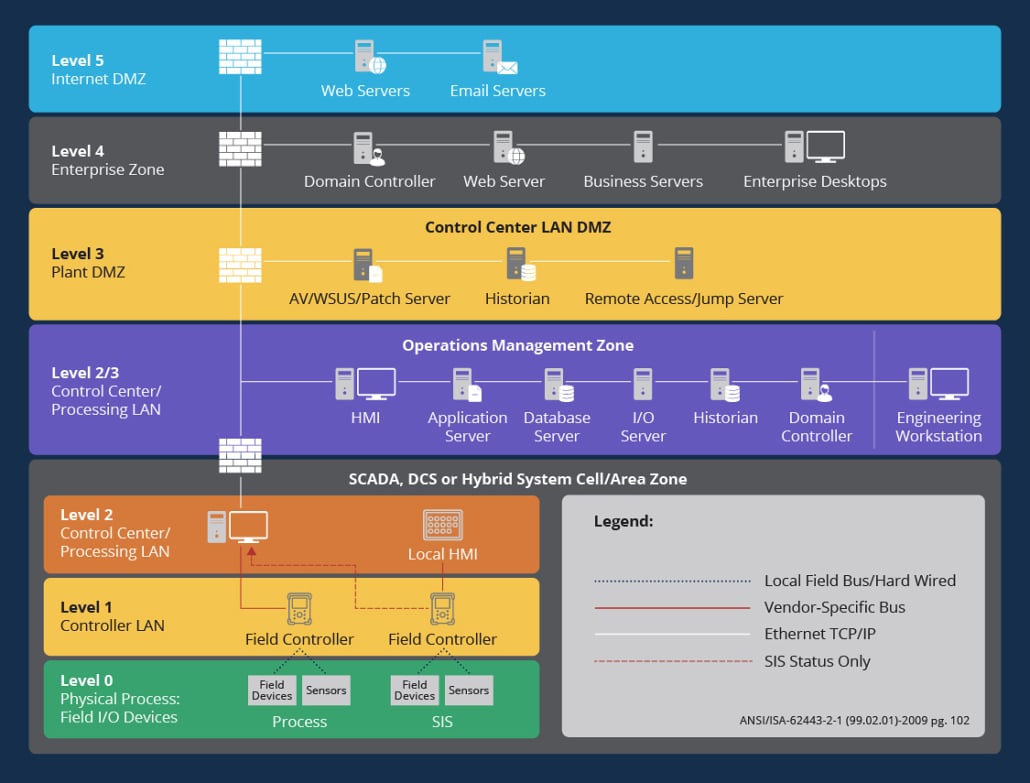
Exploring the Implications of the New National Cyber Strategy: Insights from Security Experts
In March 2023, the Biden Administration announced the National Cybersecurity Strategy, which takes a more collaborative and proactive approach.
RedSeal teamed up with cyber security experts, Richard Clarke, founder and CEO of Good Harbor Security Risk Management, and Admiral Mark Montgomery (ret.), senior director of the Center of Cyber and Technology Innovation, to discuss the latest strategy. Both have developed previous national cybersecurity strategies so we couldn’t be more privileged to hear their take on the newest national strategy’s impact on cybersecurity regulations. This blog covers the importance of harmonizing the rules, trends in resilience planning, the role of cyber insurance, the transfer of liability, and the need to keep pace with AI and quantum computing. Keep reading to learn more, or click here to listen in.
Expanding Cybersecurity Regulations
Although this is the first time the administration gives a clear and intentional nod to cybersecurity regulations, the federal government has regulated every other major sector for over 20 years. This step makes sense. Clarke points out, sectors with heavy cyber regulations have fared better in the past two decades than those without. Montgomery predicts that most changes will happen in areas where regulations are lagging, such as water, oil pipelines, and railroads.
But many agencies don’t have the resources for effective enforcement. The government must thus use a combination ofregulations, incentives, and collaboration to achieve meaningful outcomes.
The Importance of Harmonizing the Rules
The new strategy aims to “expand the use of minimum cybersecurity requirements in critical sectors to ensure national security and public safety and harmonize regulations to reduce the burden of compliance.” But the expansion of cybersecurity regulations must come hand in hand with better coordination.
Clarke observes, today’s regulations aren’t well-coordinated. Agencies must share lessons learned and align their approaches. Private sectors will benefit from the standardization of various regulations to streamline compliance, reducing cybersecurity complexity and lowering costs.
However, coordination and standardization doesn’t mean a one-size-fits-all solution. Agencies must tailor their regulations to each specific sector. The good news is that we can apply the same network security technologies to any industry and encourage knowledge-sharing across verticals. For instance, we can take the high standards from the defense industry and apply them to healthcare and transportation without reinventing the wheel.
A Focus on Resilience Planning
The cybersecurity definition of resilience has evolved as the world has become more digital. We will get hacked. It is a certainty. Instead of only looking to protect systems from attacks, regulatory mandates must also focus on prompt recovery. The government should also hire industry experts to assess digital resilience plans and stress-test them for reliance.
Cyber resilience must be applied to national security as well as private business. Transportation infrastructure must be able to operate without extended interruption. The economy (e.g., the power grid and financial systems) is our greatest weapon, and must keep functioning during conflicts and crises. Lastly, we must have the tools to quickly and effectively battle disinformation, a new frontier in the fight against nation-state threats.
The Impact of the Internet of Things (IoT)
Regulations must also cover IoT devices, but focus on the networks instead of the thousands of individual endpoints. Clark suggests that organizations should install sensors on their networks and conduct regular vulnerability scans. Montgomery adds to this, emphasizing the need for certification and labeling regimens as part of a long-term plan to make vendors responsible for their products’ performance and security.
Shifting Liability to Vendors
Speaking of making vendors responsible for their products’ performance and security, the new strategy intends to transfer liability to software vendors to promote secure development practices, shift the consequences of poor cybersecurity away from the most vulnerable, and make our digital ecosystem more trustworthy overall.
Clarke agrees that this approach is necessary, but holds that the current regulatory framework can’t support the legal implementation. IT lobbyists, some of the most well-funded and influential players on Capitol Hill, will make enforcement of such a shift an uphill battle. Clarke believes that, unfortunately, this hard but necessary shift may not happen until a tragedy shakes the nation and leaves it the only way forward.
Keeping Pace with AI and Quantum Computing
We, as a nation, have many issues to consider around AI, including beyond security. Clarke points out that we must establish rules about transparency: what’s the decision-making process? How did AI get to a conclusion? Is it searching an erroneous database? Is the outcome biased? Large language models (LLMs) are constantly learning, and adversaries can poison them to impact our decision-making.
While AI is the big problem of the moment, we can’t afford to continue ignoring quantum encryption challenges, cautions Montgomery. We have already fallen behind and must spend a substantial sum today to prepare for what’s in store in 10 years. We must start building quantum security into our systems instead of attempting to jury-rig something on later, adds Clarke.
The Rise of Cyber Insurance and Real-time Monitoring
Montgomery predicts that, if run properly, the cyber insurance market can bring these pieces together. Insurance companies may, for instance, encourage proactive measures by reducing premiums for organizations that invest in cybersecurity upfront and establish a track record of reliability and resiliency.
But organizations must prove they’re continuously protected instead of merely showing “point in time” compliance to take advantage of lower premiums. Real-time monitoring will play a critical role in lowering premiums and maintaining cybersecurity.
A Step in the Right Direction
The new National Cyber Strategy introduces timely and much-needed shifts. We must harmonize regulations to maximize the benefits without overburdening the private and public sectors.
In anticipation of the impending changes, organizations must approach their cybersecurity strategies proactively and implement the right tools and services to stay compliant. These include a comprehensive network security solution for complete visibility and ongoing monitoring, cloud security tools to protect all IT assets, and professional services to ensure airtight implementation and continuous compliance.
RedSeal has extensive expertise and experience in delivering government cybersecurity and compliance solutions. Get in touch to see how we can help you stay ahead in today’s fast-evolving digital environment.